SearchSci
SearchSci was a web-based research experiment investigating the effects of cognitive bias on our consumption of information online.
Users interacted with a simulated search engine in order to complete three related tasks:
- Search generation: brainstorming possible keyword searches related to genetically modified organisms (GMOs)
- Search selection: selecting from a predetermined list of keyword searches on the same topic
- Content: browsing and reading a predetermined set of result documents about GMOs
The scope of the experiment was expanded several times over the lifetime of the project. A conditional Memory task was added, requiring users to answer comprehension questions about documents they had read. In order to reproduce the initial experiment results, additional workflows with different task orders and minor variations on task presentation were introduced.
The user’s journey
Experiment subjects were recruited on social media as well as from Mechanical Turk. New users were directed to the landing page of the experiment’s website, shown in the screenshot above.
Entrance survey
Before starting the experiment’s tasks, users were asked to complete an entrance survey in Qualtrics (shown below). The survey was embedded in an iframe in order to maintain a consistent look and feel throughout the experiment.
Starting the experiment
After completing the entrance survey, the user had to wait 24 hours to start on the three tasks. The system notified users by email (shown below) when they could begin.
The email linked to another landing page (shown below) with general instructions for the experiment. Each task screen was also preceded by a per-task instructions screen (not shown).
Search generation
The first task was search generation. Users were asked to enter search terms “regarding things you want to know about GMOs (genetically modified organisms)”, as shown in the screenshot below. After entering five search terms, the user was allowed to proceed to the next screen.
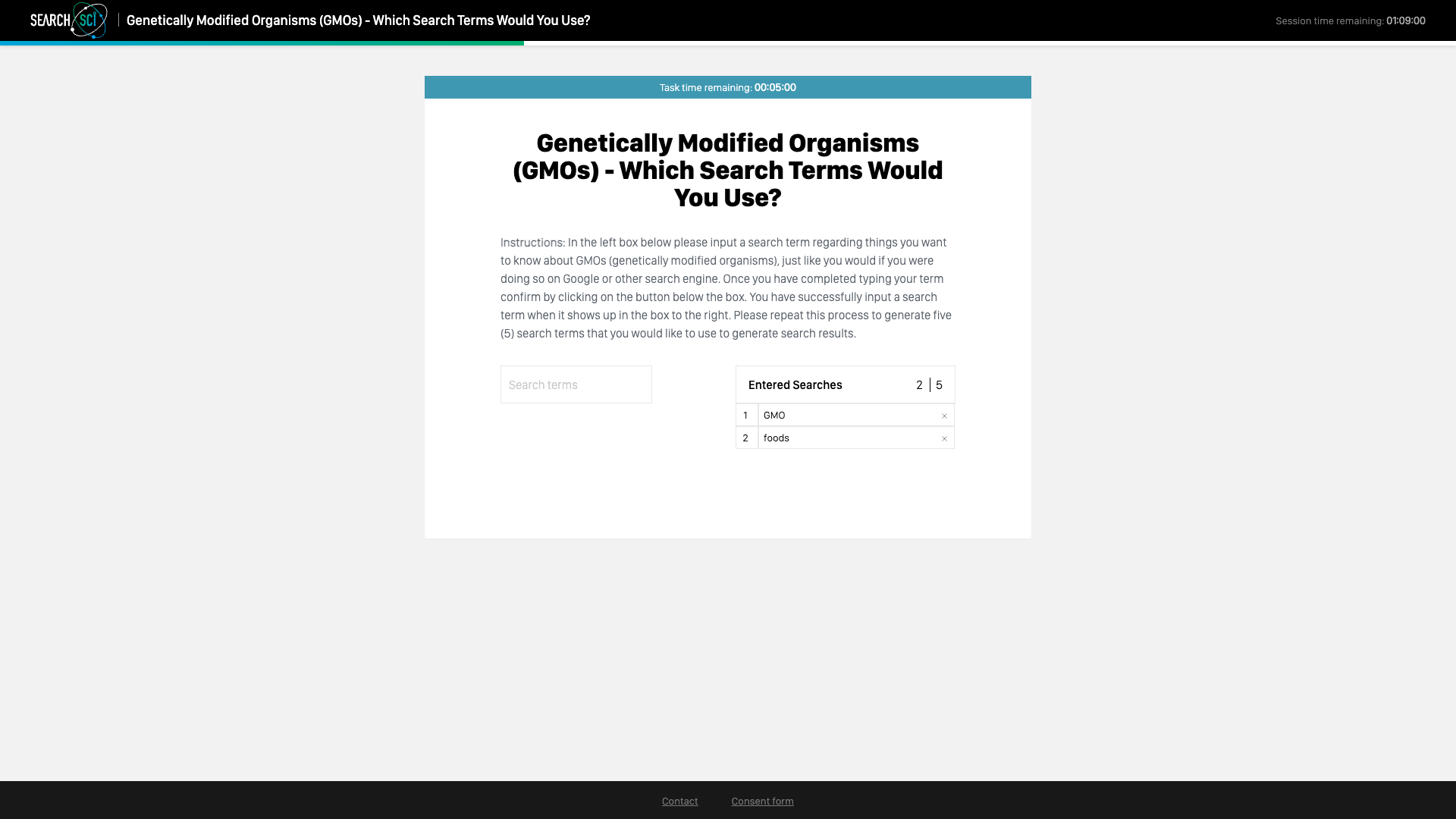
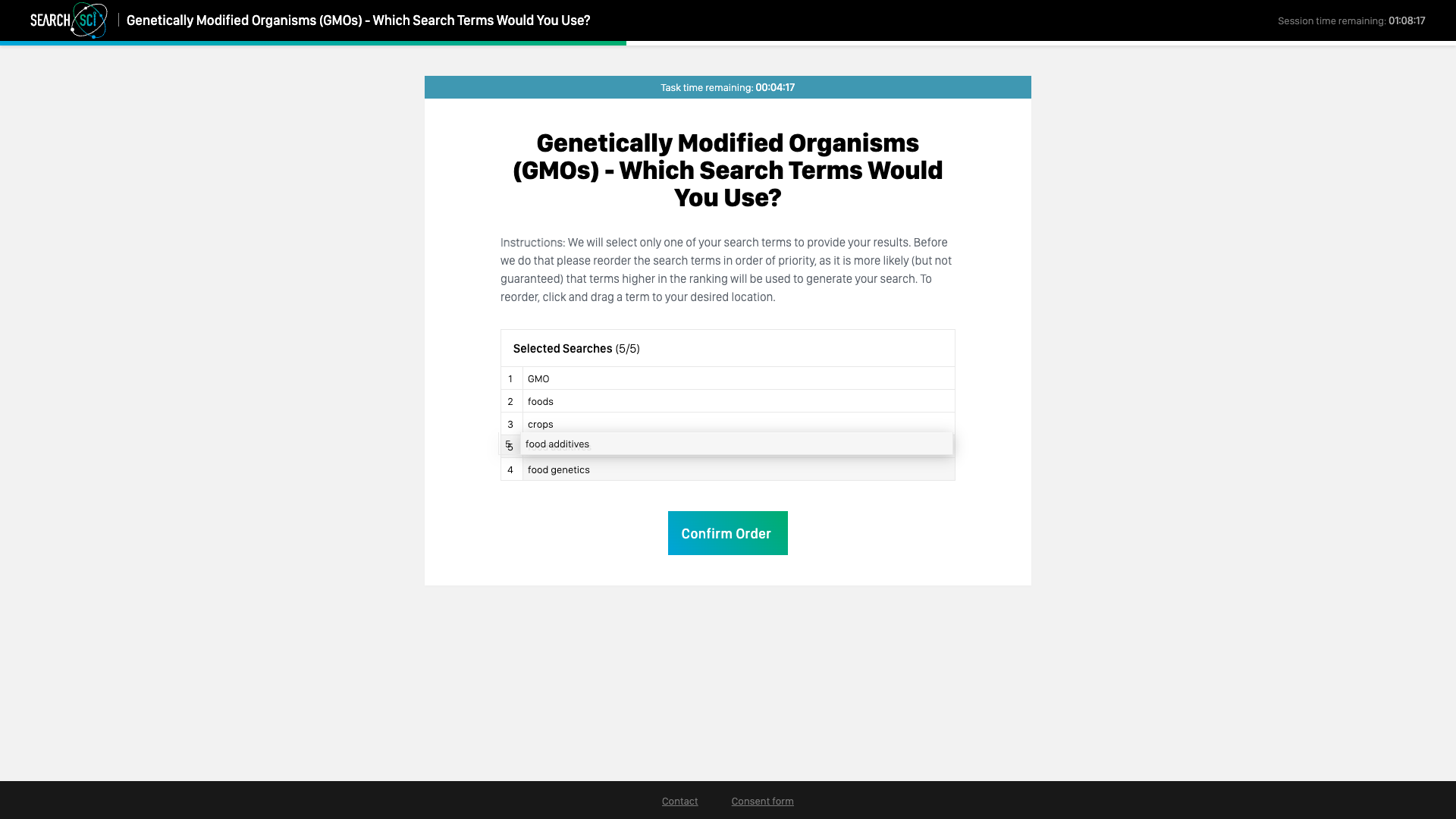
The follow-up screen (below) prompted the user to reorder the search terms they entered from most to least important, and then confirm the order. Items in the list could be dragged and dropped to reorder them.
Search selection
The next task was search selection, shown in the screenshot below. The user was prompted to select from a list of “search terms that others have used to search for information about GMOs”.
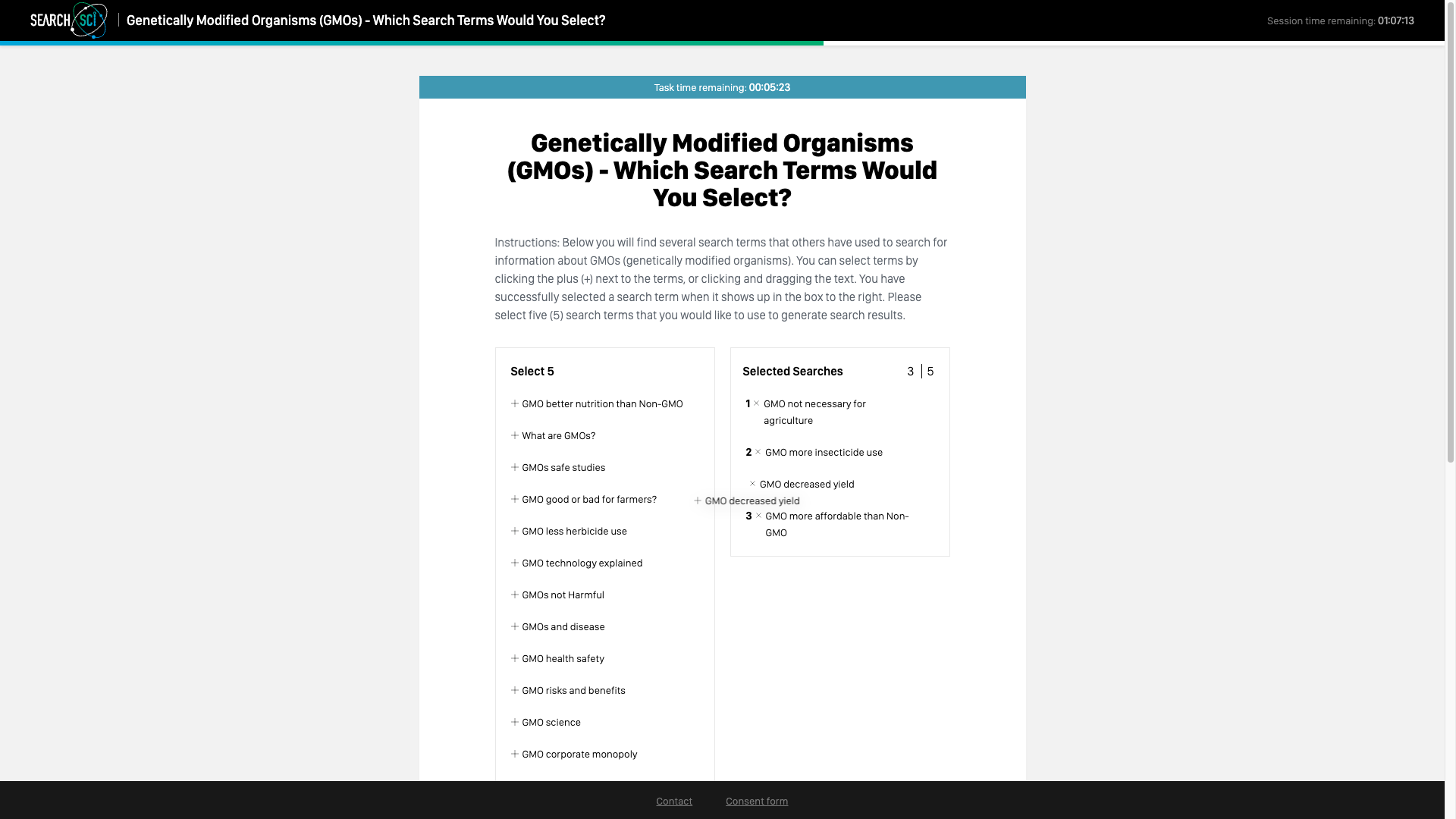
After selecting five search terms and clicking a button to proceed, the user was then asked to reorder the selected terms using the same mechanism as before.
Content task
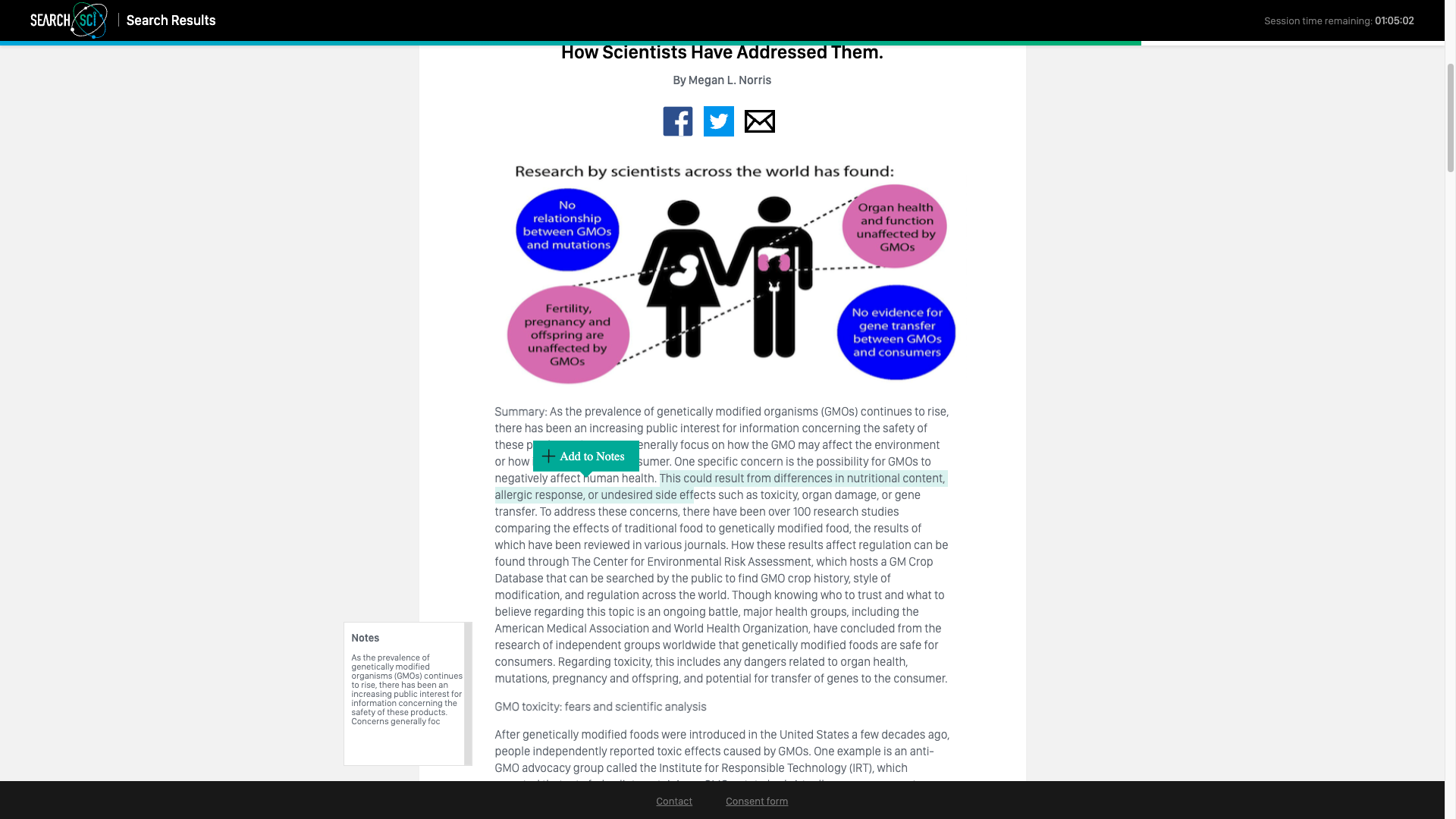
Finally, the user was directed to the content task, which presented a list of simulated search results (below).
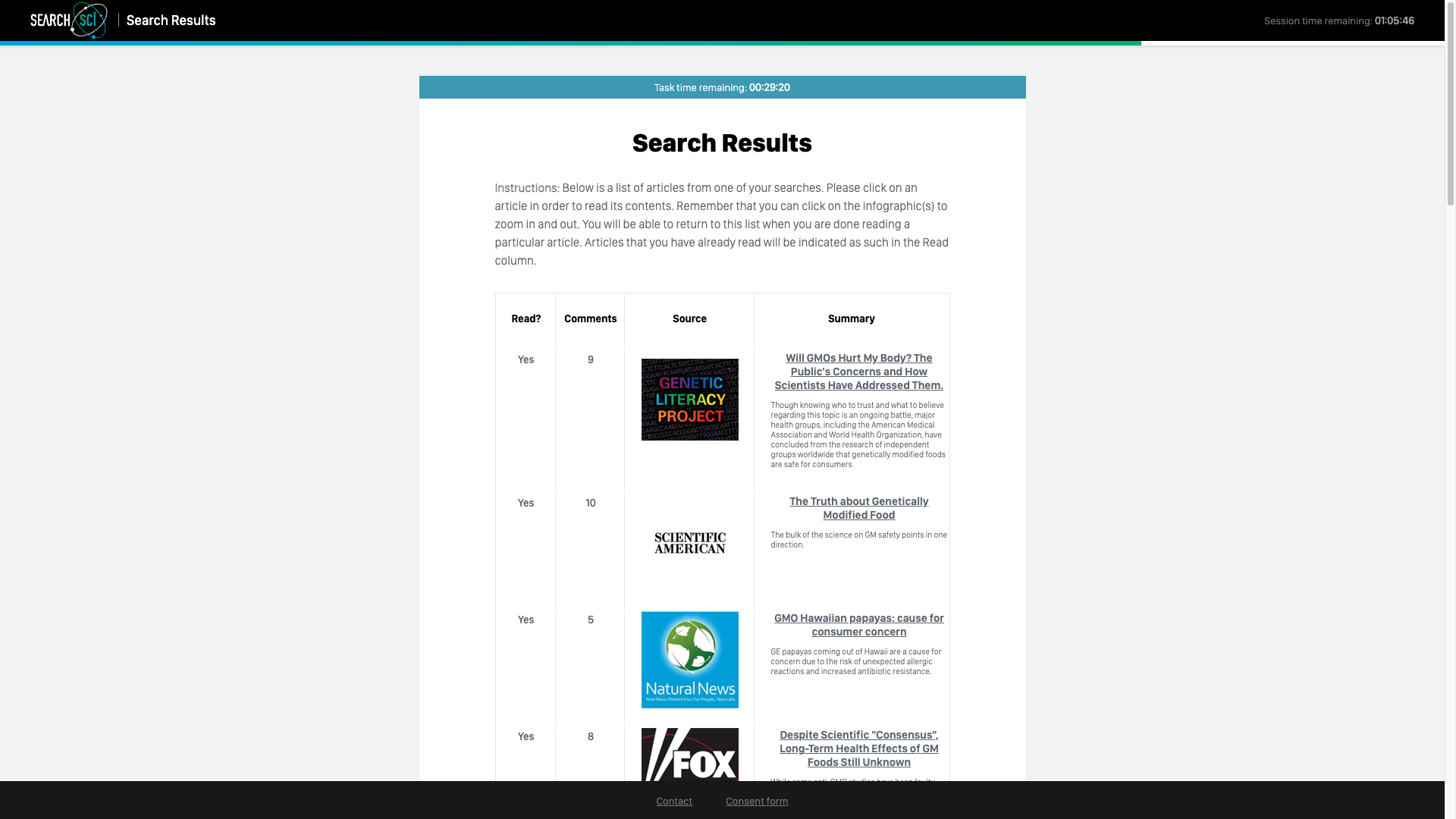
In order to successfully complete the task, the user was asked to read at least three articles within a configured time period. Users could highlight passages of an article’s text and add them to a notes box, as shown above.
When the preallocated time for completing the content task expired, a modal dialog indicated that the session was complete, and the user was directed to a page thanking them for participating in the experiment. Users who successfully completed all tasks were directed to an exit survey in Qualtrics (not shown).
Implementation
Process
At project kickoff the product owner provided a high-level write-up of initial project goals, which formed the basis for further requirement elicitation. Through subsequent discussions the product owner and I identified a set of concrete user stories for a prototype with unstyled screens – an end-to-end release 0.
I developed the prototype and subsequent releases iteratively, gathering feedback from the product owner after each release. We collaboratively refined the initial requirements and identified new requirements for later releases.
During development the product owner consulted with a user interface/user experience designer for guidance on the application’s interface. When the latter was functionally complete the designer provided a set of screen mockups with exact colors, fonts, layout, and other styling for me to apply.
Technologies
I implemented SearchSci as a three-tier web application using my then-preferred software stack:
- Knockout.js and TypeScript for the browser-based user interface
- Java middleware for translating API calls from the browser into database queries and mutations
- MongoDB document store for dynamic state
- File-based configuration in YAML
- Docker deployment on a cloud virtual machine
- Python scripting for administrative tasks as well as for extracting results from the database and preprocessing them
Challenges
The development of SearchSci presented a number of challenges, including:
- Pixel-perfect screens. Before SearchSci I rarely needed to implement pixel-perfect screens with completely custom CSS; a CSS framework such as Bootstrap was usually sufficient. For SearchSci the user interface designer wanted a more polished look than a framework could provide.
- Tracking client state. The product owner wanted to be able to analyze the actions a user took in the process of completing a task, and not just the end result. That required the browser-based interface to send frequent state updates to the middleware in the background.
- Enforcing the workflow. Users hit the browser back button, lost network connections and returned to previous pages, and so on. The system had to ensure that a user could resume an incomplete task but not update a complete one.
- Timestamps and timers. Each task was timed and the experiment session as a whole was timed. Timestamp information was included in each state update from the browser, and used as the basis for calculating the remaining time for a task and the session. After several public releases it became apparent that some users’ machines had significant clock skew, so updates were timestamped on both the client and server.
- Integrations. The web application needed to integrate with Qualtrics, preserving the Qualtrics-assigned user ID from the embedded entrance survey and passing information to the Qualtrics exit survey. The application also needed to accommodate multiple means of recruiting users, and integrate with Mechanical Turk’s reward and feedback system.
Conclusion
The SearchSci web application was successfully deployed over a period of several years and used by hundreds of experiment subjects. Although the code base grew more complex as the scope of the experiment expanded, there were no major issues with availability or data integrity.